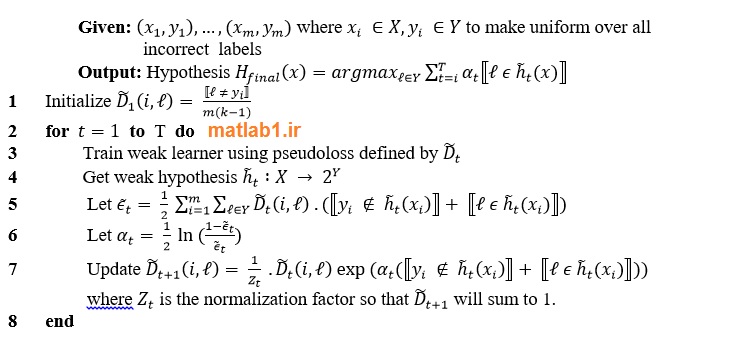اولین الگوریتم تعمیم یافته AdaBoost برای حل مسائل چندکلاسه، الگوریتمAdaBoost.M1 [36] است. نیاز به تولید خطای وزندار بهتر از در هر دور از اجرای الگوریتم AdaBoost ، اولین مانعی بود که در راستای تعمیم AdaBoost برای حل مسائل چندکلاسه وجود داشت. برای اکثر مسائل چندکلاسه k > 2 ، برقراری این شرایط بسیار سختتر از موارد حدس تصادفی است؛ بنابراین بایستی از دستهبندیکنندههای قویتری مانند C4.5 استفاده کرد که این دستهبندیکنندهها باعث بالا رفتن زمان آموزش میشود. اخیرا آیبیل و فایفر [37] و زو و همکاران [38] به ترتیب روشهای AdaBoost.MW و SAMME را پیشنهاد کردند. تغییراتی که آنها در AdaBoost ایجاد کردند، باعث شد که دستهبندیکنندههای ضعیفی تولید شود که خطای آنها اندکی بهتر از حدس تصادفی باشد.
روییند و شپیر [22] نیز یک روش قوی به نام AdaBoost.M2 ارایه کردند که قدرت آن در این نکته است که نهتنها نمونههای سخت را یاد میگیرد، بلکه برچسب کلاسهای نادرست را هم یاد میگیرد؛ به این صورت که یک توزیع برای نمونههای اشتباه تعریف میشود تا روند آموزش و تقویت با هم تلفیق شوند. این امر توسط تعریف مجموعه محتمل[1] که و کل مجموعه برچسب کلاسها است انجام میشود؛ سپس فرضیه ضعیف[2]، یک پیشبینی دوگانه برای نمونه x انجام میدهد که این پیشبینی صرفا مشخص میکند که نمونه، عضو مجموعه محتمل است یا نه. خروجی فرضیه ضعیف، به صورت شبه-زیان[3] است. فرضیهای که کمترین شبه-زیان را روی همه مجموعههای محتمل ممکن کسب کند به عنوان فرضیه برگزیده در دور t انتخاب میشود. با این شیوه، AdaBoost.M2 تضمین میکند که بهترین فرضیه ممیزی را در هر دور ارایه کند.
[1] Plausible set
[2] Weak hypotheses
[3] Pseudo-loss
الگوریتم 2. شبه کد AdaBoost.M2 را نشان میدهد.