با گسترش روز افزون شبکۀ جهاني اينترنت، يافتن اسناد مرتبط با نياز اطلاعاتي کاربران روز به روز دشوارتر مي گردد. براي يافتن اسناد مرتبط با نياز اطلاعاتي کاربر که در قالب پرس و جوي او مطرح مي شود، از يک الگوريتم رتبه بندي استفاده مي گردد. الگوريتم رتبه بندي ميزان تشابه هر سند با پرس و جوي کاربر را محاسبه مي کند. سپس اسناد بر اساس اين مقدار محاسبه شده مرتب و به کاربر ارائه مي شوند.
در اين پروژه سعي خواهد شد تا روشي نو براي رتبه بندي اسناد ارائه شود. براي اين منظور از روش معرفي شده در [1] استفاده خواهد شد. در اين روش عبارات يک سند با استفاده از يک هستان شناسي به نمونه هاي مفهومي متناظر با آنها نگاشت مي شوند و برچسب هاي سند استخراج مي گردند. سپس مشابه با روش فضاي بردار براي هر سند يک بردار ساخته مي شود که برچسب هاي توليد شده براي هر سند مولفه هاي آن را تشکيل مي دهند. وزن مولفه هاي اين بردار با پردازش آماري سند محاسبه مي شود. براي پردازش پرس و جو نيز ابتدا عبارات آن استخراج و سپس با استفاده از يک هستان شناسي مفاهيم مرتبط با اين عبارات به دست مي آيد. اين عبارات و مفاهيم، بردار پرس و جو را تشکيل مي دهند. سپس با استفاده از ضرب داخلي دو بردار، ميزان شباهت سند و پرس و جو محاسبه مي شود.
در ادامه کار انجام شده در [1]، در اين پروژه از شبکه عصبي براي رتبه بندي اسناد استفاده خواهد شد. اين شبکه داراي سه نوع گرۀ پرس و جو، عبارت، سند و دو نوع يال پرس و جو-عبارت و سند-عبارت مي باشد. وجود يال بين يک عبارت و پرس و جو ووجود يال بين يک عبارت و سند به ترتيب نشان دهندۀ ظهور آن عبارت در پرس و جو و در سند مي باشد. با پردازش آماري سند و پرس و جو وزني براي اين يال ها محاسبه خواهد شد.
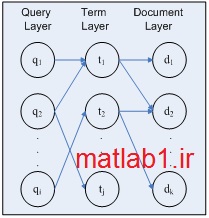
عملکرد شبکه به شرح زير است:
ابتدا با قرار دادن يک در مقدار خروجي يک گرۀ پرس و جو، آن گره، فعال مي گردد. در نتيجه همگي يال هاي خروجي آن گره فعال مي شوند. سپس حاصل ضرب وزن يال در مقدار خروجي گره به گره هاي عبارت متصل به آن گرۀ پرس و جو منتقل مي شود. از آنجا که تنها يک پرس و جو فعال است، هر عبارت تنها يک يال ورودي فعال خواهد داشت. در مرحلۀ بعد، گره هاي عبارت و يال هاي متصل کنندۀ آنها به اسناد فعال مي شوند. در نتيجه وزن هر گرۀ سند از حاصل جمع وزن گره هاي عبارت متصل به آن به دست مي آيد. اين مقدار ميزان ارتباط سند با پرس و جوي کاربر را نشان مي دهد. اما از آنجا که شبکه هاي عصبي قابليت يادگيري و تغيير دارند، مي توانند بر اساس علايق کاربر در يک دوره، متحول شوند. به همين جهت مي توان از آنها براي پياده سازي مدل باز خورد ارتباط استفاده کرد. براي اين منظور مجموعۀ جديدي از يال ها به شبکه اضافه مي شود. جهت يال هاي جديد از گره هاي سند به گره هاي عبارت است. بدون استفاده از بازخورد ارتباط شبکه در دو مرحله عمل مي کند. در مرحلۀ اول اطلاعات از گرۀ پرس و جو به گره هاي عبارت و در مرحلۀ دوم اطلاعات از گره هاي عبارت به گره هاي سند منتقل مي شود. در صورت استفاده از بازخورد ارتباط عمليات ادامه پيدا مي کند. در مرحلۀ سوم اطلاعات از گره هاي اسنادي که مرتبط با پرس و جو ارزيابي شده اند به گره هاي عبارت منتقل مي گردد. اسناد مرتبط به صورت دستي انتخاب مي شوند يا n سند اول بازيابي شده مربوط به پرس و جو در نظر گرفته مي شوند. در مرحلۀ چهارم گره هاي عبارت فعال مي شوند و وزن جديد آنها از طريق يال هاي پرس و جو-سند، به اسناد منتقل مي شود. در نتيجه اسناد وزن جديدي به دست مي آورند.
در مدل بازخورد ارتباط از اطلاعات اسنادي که مرتبط با يک پرس و جو ارزيابي شده اند، براي بهبود نتايج همان پرس و جو استفاده مي شود. بنابراين پرس و جوهاي بعدي يک رويداد جديد هستند و از هيچ گونه اطلاعات قبلي براي بازيابي اسناد مرتبط با آنها نمي توان استفاده کرد. اما در شبکۀ عصبي، براي به کارگيري اطلاعات قبلي، به گره هاي اسناد يک متغير اختصاص داده مي شود. در صورتي که کاربر سند را مرتبط ارزيابي کند، اين متغير مقدار يک و اگر سند را غير مرتبط ارزيابي کند، مقدار منفي يک خواهد داشت. اگر کاربر قضاوتي در مورد سند نکند، مقدار اين متغير صفر خواهد بود. سپس وزن يال هاي عبارت-سند به صورت زير اصلاح مي شود:
اختلاف وزن يک سند و متغير مذکور را به دست آورده و به وزن کليۀ يالهاي متصل به آن اضافه مي گردد. البته اسنادي که داراي وزن بالايي هستند، شبکه را چندان تغيير نمي دهند. اما اسناد با وزن پايين که مرتبط ارزيابي شده اند، تغييرات بيشتري در شبکه ايجاد مي کنند.
[1] S.Motiee, A. Nematzadeh, M.Shamsfard, “A Hybrid Ontology Based Approach for Ranking Document”, “Proceedings of the 11th International Conference on Computer Science “, ICCS2006, Prague, Czech Republic, 24-26 February, 2006.
[2] David A.Grossman, Ophir Frieder. “Information Retrieval Algorithms and Heuristics”. Second ed.. Springer. 2004.