تشخيص صدا يا شناسايي گوينده (Speaker Identification) يکي از مسايل علوم رايانه و هوش مصنوعي است که هدف آن شناسايي يک فرد تنها از روي صداي شخص است. يکي از اصليترين ابزارهاي رياضي براي حل اين مسئله مدل هاي پنهان مارکوف هستند. براي حل اين مسئله با استفاده از مدل پنهان مارکوف (م.پ.م) اين مدل هاي آماري ابتدا بايد مورد آموزش قرار بگيرند. براي اين مرحله ابتدا مقدار قابل توجهي از صداي ضبط شده افراد پردازش ميشود. دادههاي پردازش شده که در حقيقيت مجموعه عظيمي از اعداد ميباشند متناوباً مورد استفاده قرار ميگيرند تا م.پ.م. براي هر گوينده به دست آيد.
در حقيقت م.پ.م.ها مانند يک ماشين عمل ميکنند که ورودي آنها يک سري داده است و خروجيشان يک عدد براي هر مجموعهاي از دادهها ، به اين صورت که آن عدد نشان دهنده اختلاف دادههاي ورودي با م.پ.م هر ماشين است. براي آموزش م.پ.م در هر تناوب دادهها به م.پ.م داده ميشود و پارامترهاي م.پ.م ذرهاي تغيير داده ميشود تا عدد خروجي (که نشان دهنده اختلاف دادهها با م.پ.م است) کوچکتر شود. براي اطمينان از اينکه تغيير پارامترهاي م.پ.م در جهت درست انجام ميگيرد و نهايتا به حداقل شدن عدد خروجي ميانجامد از يک روش رياضي به نام Expectation Maximization استفاده ميشود. در نهايت بعد از آموزش اين مدلها که با استفاده از صداي مرجع انجام شده، ميتوان براي آزمايش سامانه صداي يکي از افرادي که قبلا از صداي وي براي آموزش م.پ.م استفاده شده را به هر يک از م.پ.مها داد. م.پ.م اي که کوچکترين عدد را توليد ميکند به عنوان فرد شناسايي شده در نظر گرفته ميشود.
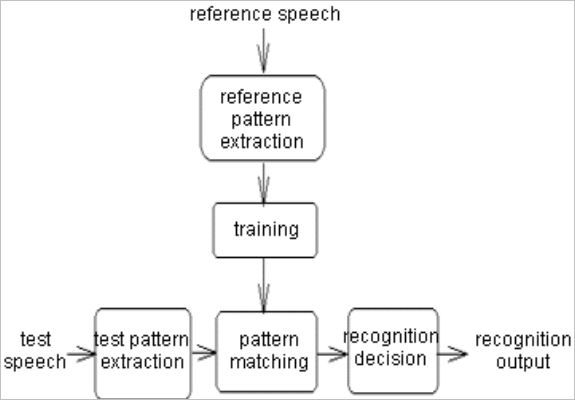
سامانه بالا به دلايل مختلفي احتمال خطا دارد. شباهت صداي افراد به يکديگر ( که گاهي انسان ها را نيز به اشتباه مياندازد )، صداهاي حاشيه (نويز)، محدوديت حجم دادههاي مرجع براي آموزش و غيره از جمله اين اشتباهها هستند. براي بالا بردن ضريب اطمينان سامانه شناسايي گوينده روشهاي مختلفي بکار ميرود که هر ساله نيز با پيشرفت تحقيقات در دنيا به آنها اضافه ميشود. از جمله استفاده ترکيبي از تشخيص گفتار و تشخيص صدا که در آن نه تنها صداي گوينده بلکه کلمه(هاي) وي نيز مورد آزمايش قرار ميگيرند. گوينده بايد کلمات مشخصي را بکار ببرد تا سامانه به وي اجازه عبور بدهد.
همچنين ميتوان از يک عدد حداکثر براي مقايسه اعداد خروجي م.پ.م استفاده کرد بطوري که م.پ.م مورد نظر نه تنها بايد کوچکترين عدد را بدهد بلکه بايد اين عدد از يک عدد مرجع نيز کوچکتر باشد. در نتيجه اين تغيير در سامانه ضريب ايمني سامانه بالا ميرود. اين ضريب ايمني به قيمت بالا رفتن درصد ردّ افراد از روي خطا صورت ميگيرد و باعث ميشود شخصي که به او بايد اجازه عبور داده شود چند بار رمز خود را براي سامانه تکرار کند. مانند تمام سامانههايي بهينهسازي پارامترهاي مختلف براي بهترين عملکرد سامانه در شرايط مورد نياز لازم است. (به عنوان مثال در ورودي اتاق کنترل يک نيروگاه هستهاي نياز به حفاظت زيادي دارد که ممکن است در مورد درب ورودي کتابخانه دانشگاه نياز نباشد.)
مدل مخفي مارکوف
