
پردازش داده های بزرگ با آپاچی اسپارک
اسپارک چیست؟
آپاچی اسپارک یک فریم ورک متن باز برای پردازش داده های بزرگ است که بر پایه سرعت، استفاده آسان و تحلیل های پیچیده ساخته شده است. این برنامه در ابتدا در سال 2009 در آزمایشگاه AMP دانشگاه برکلی[1] توسعه یافت و سپس در سال 2010 به عنوان پروژه ای از آپاچی، به برنامه ای متن باز تبدیل شد.
اسپارک مزیت های بسیاری نسبت به دیگر برنامه ها ی داده بزرگ و فن آوری های MapReduce مانند هدوپ و استورم دارد. اول از همه، اسپارک یک چارچوب یکپارچه برای الزامات مدیریت پردازش داده های بزرگ به همراه تنوع وسیعی از مجموعه داده [2] هایی که همانند منبع داده ها (batch v. real-time streaming data)، در ماهیت، یکتا هستند (داده های متنی، نموداری و غیره) را در اختیار ما می گذارد. اسپارک، برنامه های درون خوشه های هدوپ را قادر می سازد تا در حافظه، با سرعتی 100 برابر و حتی بر روی دیسک، با سرعتی 10 برابر اجرا شوند. اسپارک به شما اجازه می دهد تا به سرعت، برنامه ها را در جاوا، اسکالا یا پایتون بنویسید. این برنامه به همراه یک مجموعه built-in با بیش از 80 عملگر سطح بالا عرضه می شود. علاوه بر عملگر های Map و Reduce، این برنامه از جست و جو های SQL، جریان داده ها، یادگیری ماشین و پردازش داده های نموداری پشتیبانی می کند. توسعه دهندگان می توانند از این قابلیت ها به صورت مستقل و یا از ترکیب آن ها برای اجرای یک خط داده تنها استفاده کنند.
در بخش اول سری مقالات آپاچی اسپارک، ما نگاهی بر خود اسپارک، چگونگی عملکرد آن در مقایسه با یک راه حل MapReduce معمولی، و چگونگی ارائه یک مجموعه کامل از ابزار ها برای پردازش داده های بزرگ توسط این نرم افزار می اندازیم.
هدوپ و اسپارک
هدوپ در طی 10 سال، به عنوان یک تکنولوژی پردازش داده های بزرگ مطرح بوده است و ثابت کرده که راه حلی برای پردازش مجموعه داده های عظیم می باشد. MapReduce یک راه حل فوق العاده برای محاسبات تک گذر[3] است، اما راه حل چندان موثری برای مواردی که نیازمند محاسبات و الگوریتم های چند-گذر[4] هستند، نمی باشد. هر گام در گردش کار پردازش داده ها، یک فاز Map و یک فاز Reduce دارد و شما نیاز دارید تا هر مورد را به الگوی MapReduce تبدیل کنید تا بتوانید بیشترین استفاده را از این برنامه داشته باشید.
داده های خروجی Job میان هر گام باید پیش از آغاز قدم بعدی، در فایل سیستمی توزیع شده ذخیره شود. از این رو، این رویکرد به دلیل تکرار و ذخیره سازی دیسکی، آهسته است. همچنین راه حل های هدوپ عمدتا شامل خوشه هایی هستند که برای راه اندازی و کنترل، دشوار هستند. این برنامه همچنین نیازمند ادغام چندین ابزار برای داده های بزرگ مورد استفاده ( مانند Mahout برای Machine Learning و استورم برای پردازش جریان داده ها ) است.
اگر شما بخواهید کار پیچیده ای را انجام دهید، شما باید مجموعه ای از job های MapReduce را در یک رشته قرار داده و آن ها را به ترتیب اجرا کنید. هریک از این job ها دارای تاخیر زیاد بوده و هیچ یک تا زمانی که job قبلی به طور کامل پایان نیافته باشد، نمی توانند آغاز شوند.
اسپارک به برنامه نویسان اجازه می دهد تا خط داده های پیچیده و چند مرحله ای را با استفاده از الگوی گراف مستقیم بدون دور[5] (DAG) توسعه دهند. این برنامه همچنین از اشتراک داده “درون حافظه” ای در DAG ها پشتیبانی می کند تا job های گوناگون بتوانند با همان داده ها، کار کنند.
اسپارک بر روی زیرساخت های موجود فایل سیستمی توزیع شده (HDFS) هدوپ اجرا می شود تا کاربردپذیری بیشتر و تقویت شده ای را ارائه کند. این برنامه پشتیبانی هایی را برای به کارگیری برنامه های اسپارک بر روی کلاستر فعلی Hadoop v1 cluster ( به همراه SIMR – Spark-Inside-MapReduce) یا SIMR – Spark-Inside-MapReduce فراهم می کند.
ما باید به اسپارک به عنوان جایگزینی برای Hadoop MapReduce نگاه کنیم و نه خود هدوپ. هدف این نیست که هدوپ را جایگزین کنیم، بلکه می خواهیم یک راه حل یکپارچه و جامع برای موارد استفاده مدیریت داده های بزرگ گوناگون و الزامات آن ارائه دهیم.
ویژگی های اسپارک
اسپارک MapReduce را به سطح بعدی، اما با درهم ریختگی کم هزینه تر برای پرادزش داده ها، می برد. با قابلیت هایی از قبیل ذخیره سازی داده “درون حافظه” و پردازش نسبتا در زمان واقعی[6]، عملکرد این برنامه می تواند چندین برابر سریع تر از دیگر فن آوری های داده های بزرگ باشد.
اسپارک همچنین از “ارزیابی کند”[7] در جست و جوی داده های بزرگ پشتیبانی می کند که این کار به بهینه سازی گام ها در گردش کار پردازش داده ها کمک می کند. این برنامه، سطح بالاتری از رابط برنامه های کاربردی[8] را برای بهبود بهره وری توسعه دهنده، و همچنین یک مدل معماری سازگار را برای راه حل های داده های حجیم، فراهم می کند.
اسپارک به جای این که نتایج میانی را بر روی دیسک بنویسد، آن ها را در حافظه نگه می دارد. این کار، عملی بسیار مفید، مخصوصا در هنگامی که شما نیاز دارید ت بر روی همان مجموعه داده، چندین بار کارکنید، بسیار مفید است. این برنامه طراحی شده تا موتور اجرایی باشد که هم به صورت دورن حافظه (in-memory) و هم بر روی دیسک (on-disk) کار کند. عملگر های اسپارک، عملیات های خارجی را در هنگامی که داده ها متناسب با حافظه نباشند[9]، انجام می دهند.
از اسپارک می توان برای پردازش مجموعه داده هایی که بزرگتر از حافظه جمعی[10] در یک خوشه هستند، استتفاده نمود. اسپارک تلاش کرده تا به میزان ممکن، داده ها را در حافظه جای داده و پس از آن، بر روی دیسک قرار می دهد. شما برای ارزیابی الزامات حافظه، باید به داده ها و موارد استفاده خود نگاه کنید. با این ذخیره سازی درون حافظه ای، اسپارک با مزیت عملکردی همراه می شود.
دیگر ویژگی های اسپارک شامل :
- پیشتیبانی، بیش از فقط توابع Map و Reduce.
- بهینه سازی عملگر های اختیاری نمودار ها.
- ارزیابی کند از جست و جو های داده های بزرگ که به بهینه سازی گردش کار کلی پردازش داده ها کمک می کند.
- فراهم کردن رابط کاربری برنامه ها به صورت مختصر و سازگار در اسکالا، جاوا و پایتون.
- و فراهم کردن پوسته تعاملی برای اسکالا و پایتون، می شود. این مساله هنوز برای جاوا موجود نیست.
اسپارک به زبان برنامه نویسی اسکالا نوشته شده و بر روی محیط ماشین مجازی جاوا (JVM) اجرا می شود. این برنامه هم اکنون از زبان های زیر برای توسعه برنامه های کاربردی با استفاده از اسپارک، پشتیبانی می کند:
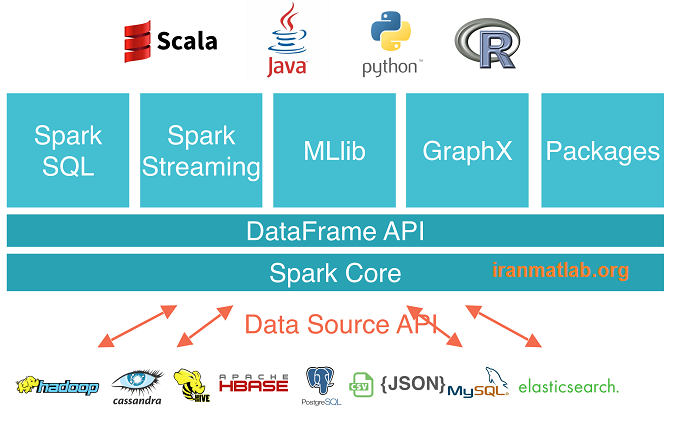
اکوسیستم اسپارک
علاوه بر رابط برنامه های کاربردی هسته اسپارک[11]، در اینجا کتابخانه های دیگری وجود دارند که بخشی از اکوسیستم اسپارک بوده و قابلیت های دیگری را در تحلیل داده های بزرگ و محدوده های یادگیری ماشین، فراهم می کند.
این کتابخانه ها شامل:
جریان سازی اسپارک[12]
جریان اسپارک می تواند برای پردازش جریان داده ها در زمان- واقعی[13] مورد استفاده قرار گیرد. این عمل، برپایه سبک پردازش و محاسبه micro batch می باشد. این برنامه برای پردازش زمان واقعی داده ها، از DStream استفاده می کند که در اصل یک مجموعه از RDD ها می باشد.
SQL اسپارک
Spark SQL قابلیت در معرض قرار گرفتن مجموعه های داده اسپارک بر روی رابط برنامه های LDBC را فراهم کرده و اجازه می دهد تا sql هایی مانند جست و جو ها، با استفاده از BI سنتی و ابزار های مجسم سازی بر روی داده های اسپارک، اجرا شوند. Spark SQL به کاربران اجازه می دهد تا داده های خود را از فرمت های گوناگونی که هم اکنون دارند (مانند JSON, Parquet ، یک پایگاه داده) ، استخراج کرده، تبدیل کرده و بارگذاری کنند و آن ها را در معرض یک جست و جوی موقت قرار دهند.
MLlib اسپارک
MLlib، کتابخانه یادگیری ماشین مقیاس پذیر اسپارک است که از الگوریتم ها و ابزار های یادگیری معمول از قبیل طبقه بندی، رگرسیون، خوشه بندی، فیلترینگ مشترک، کاهش ابعادی و همچنین بهینه سازی های اساسی اولیه، تشکیل شده است.
GraphX اسپارک
GraphX، API جدید اسپارک (ورژن آلفا) برای گراف ها و محاسبات گراف های موازی است. در سطح بالا، GraphX با معرفی نمودار املاک توزیع شده انعطاف پذیر[14]، یک نمودار چندگانه از ویژگی هایی که به هر راس و یال متصل شده است، RDD اسپارک را گسترش می دهد. برای پشتیبانی از محاسبات گراف ها، GraphX همانند متغیر بهینه شده Pregel API، مجموعه ای از عملگر های بنیادین (مانند زیرگراف، رئوس مشترک[15]، و پیام های ادغام شده[16]، را نمایش می دهد. علاوه بر این، GraphX شامل یک مجموعه رو به رشد از الگوریتم ها و سازنده های گرافی می شود که وظایف تحلیل گراف را ساده تر می سازند.
در خارج از این کتابخانه ها، موارد دیگری مانند BlinkDB و Tachyon وجود دارند.
BlinkDB یک موتور جست و جوی تقریبی بوده و می تواند برای اجرای جستجو های SQL بر روی داده های با حجم بالا، مورد استفاده قرار گیرد. این برنامه به کاربران اجازه می دهد تا دقت جستجو را با زمان پاسخ، مبادله کنند. این برنامه با اجرای جستجو ها بر روی نمونه های داده، و نمایش دادن حاصل هایی که با ستون های معنی دار خطا، همراه شده اند، بر روی مجموعه داده های بزرگ کار می کند.
تایکون نیز یک فایل سیستمی توزیع شده حافظه محور است که یک به اشتراک گذاری قابل اعتماد در سطح سرعت حافظه را در تمام فریم ورک خوشه از قبیل Spark و MapReduce فعال می سازد. تایکون، مجموعه داده های در حال کار را در حافظه به صورت کش بارگذاری کرده و از این رو برای داده هایی که مرتبا خوانده می شوند، مراجعه به دیسک را حذف می کند. این کار، job ها/جستجو های مختلف و فریم ورک ها را قادر می سازد تا به فایل های کَش شده، در سطح سرعت حافظه دسترسی داشته باشند.
همچنین در اینجا آداپتور های ادغام کننده و دیگر محصولاتی مانند کاساندرا (Spark Cassandra Connector)، و R (SparkR) نیز وجود دارند. با رابط کاساندرا، شما می توانید از اسپارک برای دسترسی به داده های ذخیره شده در یک پایگاه داده کاساندرا دسترسی پیدا کرده و تحلیل های داده را بر روی آن داده ها انجام دهید.
[2] Data set
[3] one-pass computations
[4] Multi-pass
[5] directed acyclic graph
[6] real-time
[7] در نظریه زبان برنامه نویسی، lazy evaluation یا call-by-need به نوعی از راهبرد ارزیابی گفته می شود که ارزیابی را تا هنگامی که مقدار آن مورد نیاز باشد، به تاخیر می اندازد.
[8] API
[9] به نظر می رسد منظور، ظرفیت پایین حافظه است.
[10] حافظه (مموری) های ادغام شده
[13] Real-time
[14] Resilient Distributed Property Graph
[15] joinVertices
[16] aggregateMessages