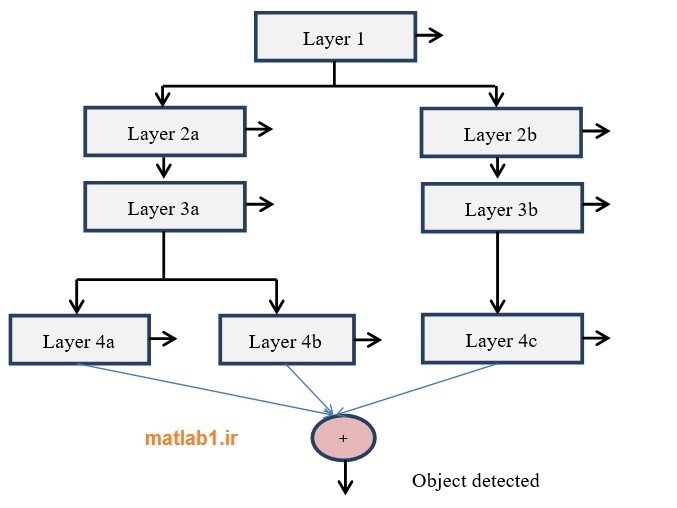
مشکل تغییرپذیری درونکلاسی برای کلاس هدف و همچنین معایب استفاده از چندین دستهبندیکننده سريال به طور همزمان، در روش ارائه شده توسط لینهارت و همکاران [49] برطرف شد. روش آنها یک ساختار درختی از دستهبندیکنندهها را پیشنهاد میکرد که در شکل زیر نمایش داده شدهاست. در هر گره[1] از این ساختار درختی، برای ساختن شاخهها، الگوریتم خوشهبندی نزدیکترین[2] اعمال میشود. وجود شاخهها باعث بهوجود آمدن دستهبندیکنندههای قدرتمندتر میشود. ایجاد شاخهها تنها در صورتی که دقت دستهبندیکننده روند صعودی داشته باشد انجام میشود؛ بنابراین، ایجاد شاخهها باعث بدتر شدن زمان اجرا و بالا رفتن پیچیدگی نمیشود.
نتایج حاکی از آن است که این روش دو برابر سریعتر از ساختار دستهبندیکنندههای همزمان و حتی سریعتر از یک دستهبندیکننده تنها است؛ همچنین دقت نیز در این روش حفظ میشود و در مواردی افزایش مییابد [49]. با این حال این ساختار معایب خاص خود را دارد. تنظیم آستانه، مخصوص ساختار سريال، در این روش وجود دارد. گره ریشه، بایستی با تمام نمونههای مثبت روبهرو شود که این ویژگی برای مواردی که مجموعه داده، پیچیده و دارای گوناگونی درونکلاسی زیادی باشد، مساله را سخت و وخیم خواهد کرد [4]. در این شرایط، تعداد دستهبندیکنندههای ضعیف به شدت افزایش خواهد یافت و تنظیم آستانه منجر به بالا رفتن نرخ بازیابی نادرست[3] خواهد شد. در نهایت، الگوریتم خوشهبندی نزدیکترین نیز ممکن است زمان آموزش را افزایش دهد.
[1] Node
[2] k-nearest clustring
[3] False detection rate